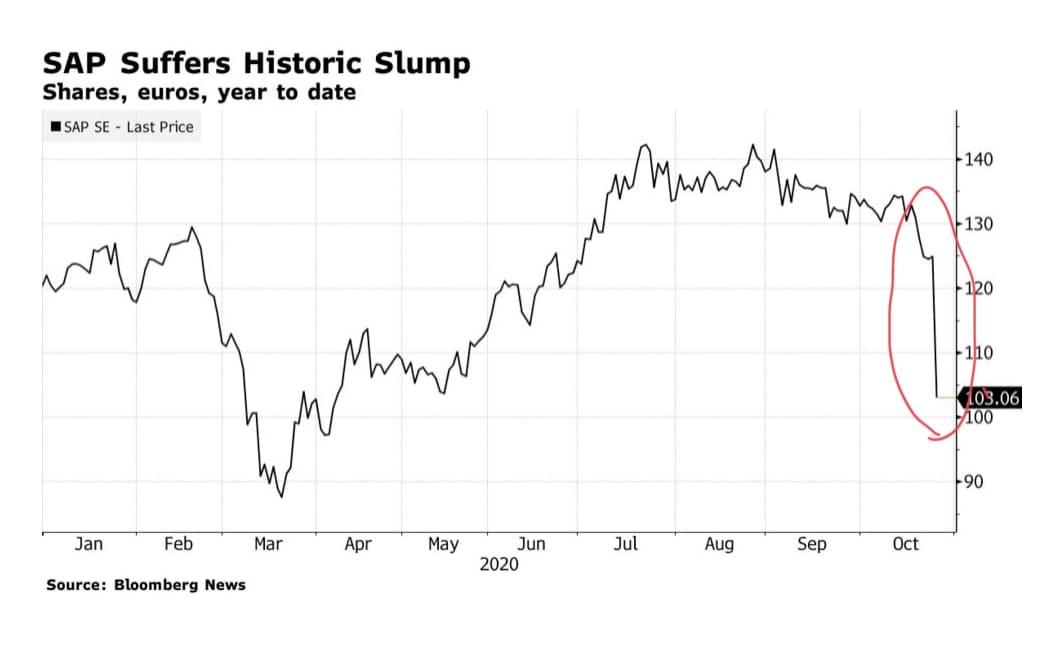
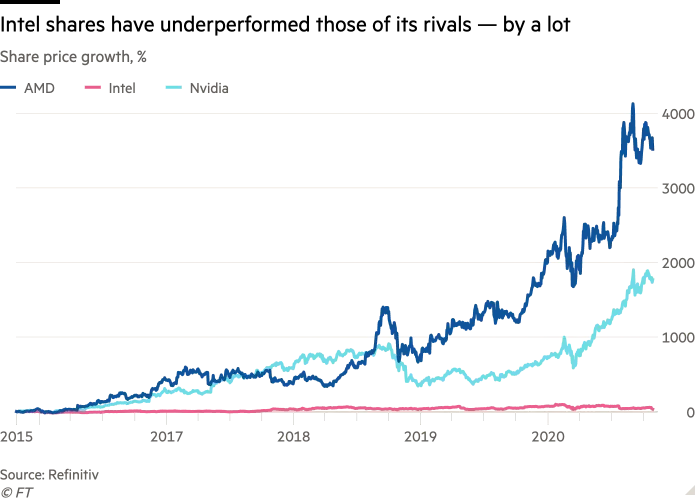
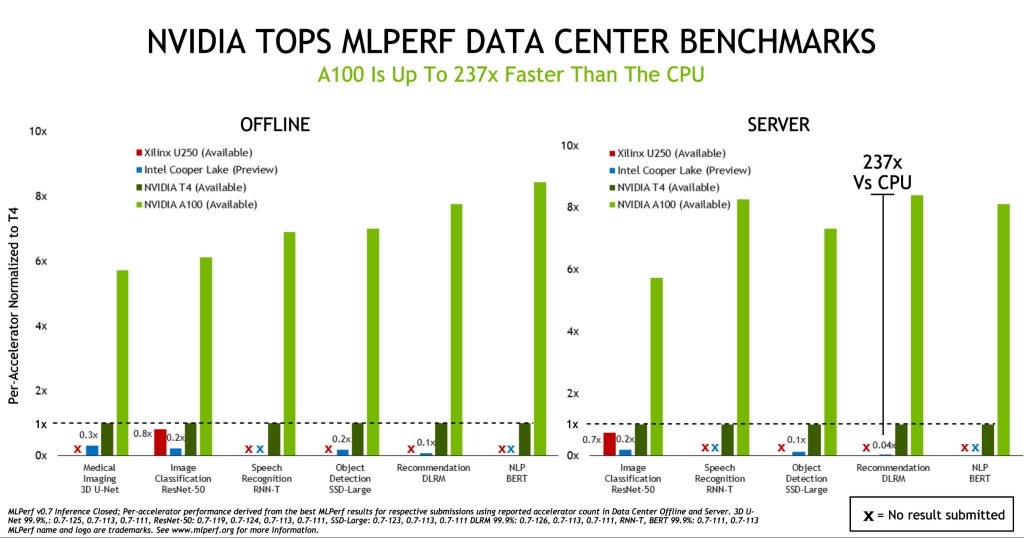
焦点:中国新一轮半导体热潮
中美技术对抗的背景下,芯片/半导体成为频繁出现在科技新闻、时政新闻以及自媒体平台上的热词,每一条消息似乎都有众多解读空间,比如:
- 2020 年 10 月 14 日,第三届全球集成电路企业家大会在上海举行;
- 2020 年 10 月 22 日,南京集成电路大学成立,这是中国首个芯片大学;
- 2020 年 10 月 26 日,工信部表示,积极考虑将 5G、集成电路、生物医药等重点领域纳入「十四五」国家专项规划;
- 2020 年 10 月 27 日,上海自贸区临港新片区「东方芯港」集成电路综合性产业基地正式启动,目标打造国内第一的芯片制造高地;
与之遥相呼应的,还有 2020 年中国注册成为半导体的公司数量变化,下图是 FT 根据企查查的数据整理而成。
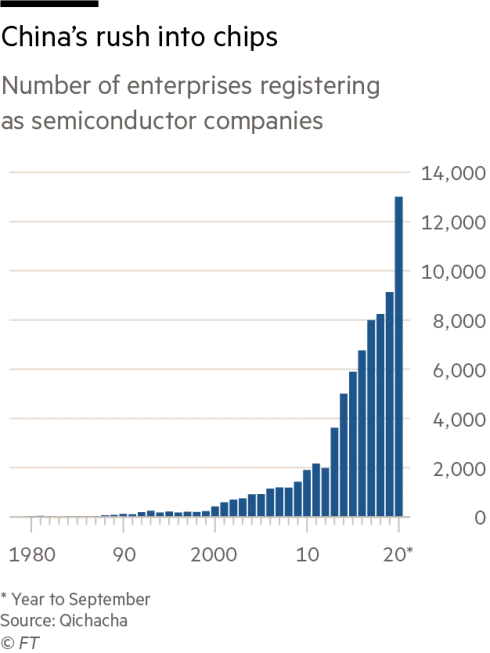
这些密集的新闻、快速增长的企业,折射出的到底是一个机会/机遇还是一个巨大泡沫,现在还是未知数。
本周出版的《中国新闻周刊》聚焦在各地此前建设的半导体项目烂尾潮。早在 2014 年,首批 1300 亿元的国家大基金投入到半导体领域,但在过去几年的时间里,一大批烂尾项目相继浮上水面,比如:
- 位于武汉市东西湖的弘芯项目;
- 位于陕西西咸新区号称要建设国内首个柔性半导体服务制造基地的陕西坤同半导体项目;
- 今年 6 月,南京德科玛因资金不足进入破产清算及资产移交程序;
这些项目烂尾的很大一部分原因是资金链的断裂,更进一步去看,过去几年,各地政府对于半导体相关产业的热衷,也加剧了市场的虚火,大量低水平的重复建设、产业发展变成了投资变现,无论是技术研发、知识产权还是人才培养,过去几年的发展几乎可以忽略不计。
也是在本周,德勤给出了一份亚太半导体市场分析报告,相对客观地勾勒出目前中国所处的产业位置,重点关注以下这些数字:
其一,中国大陆半导体产业在全球主要国家/地区的营收占比不足 5%。
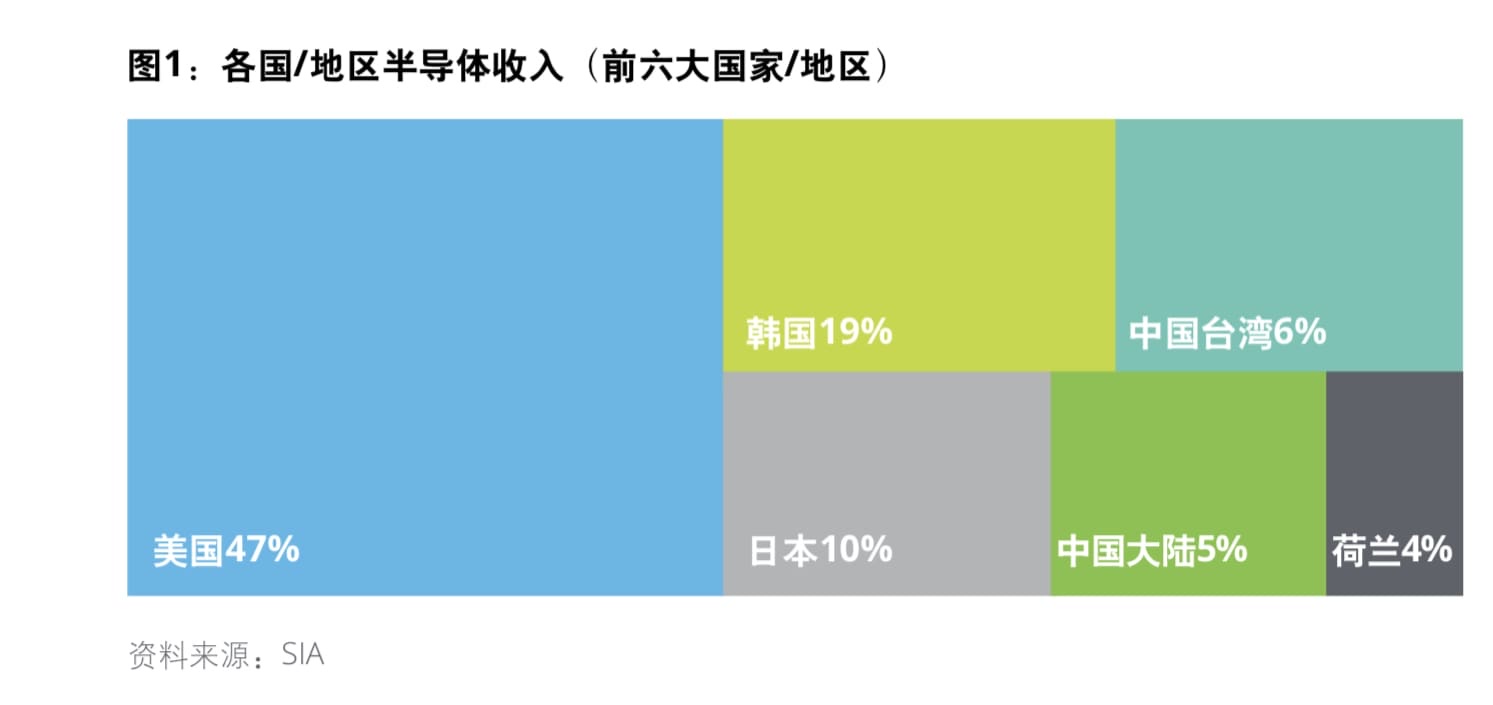
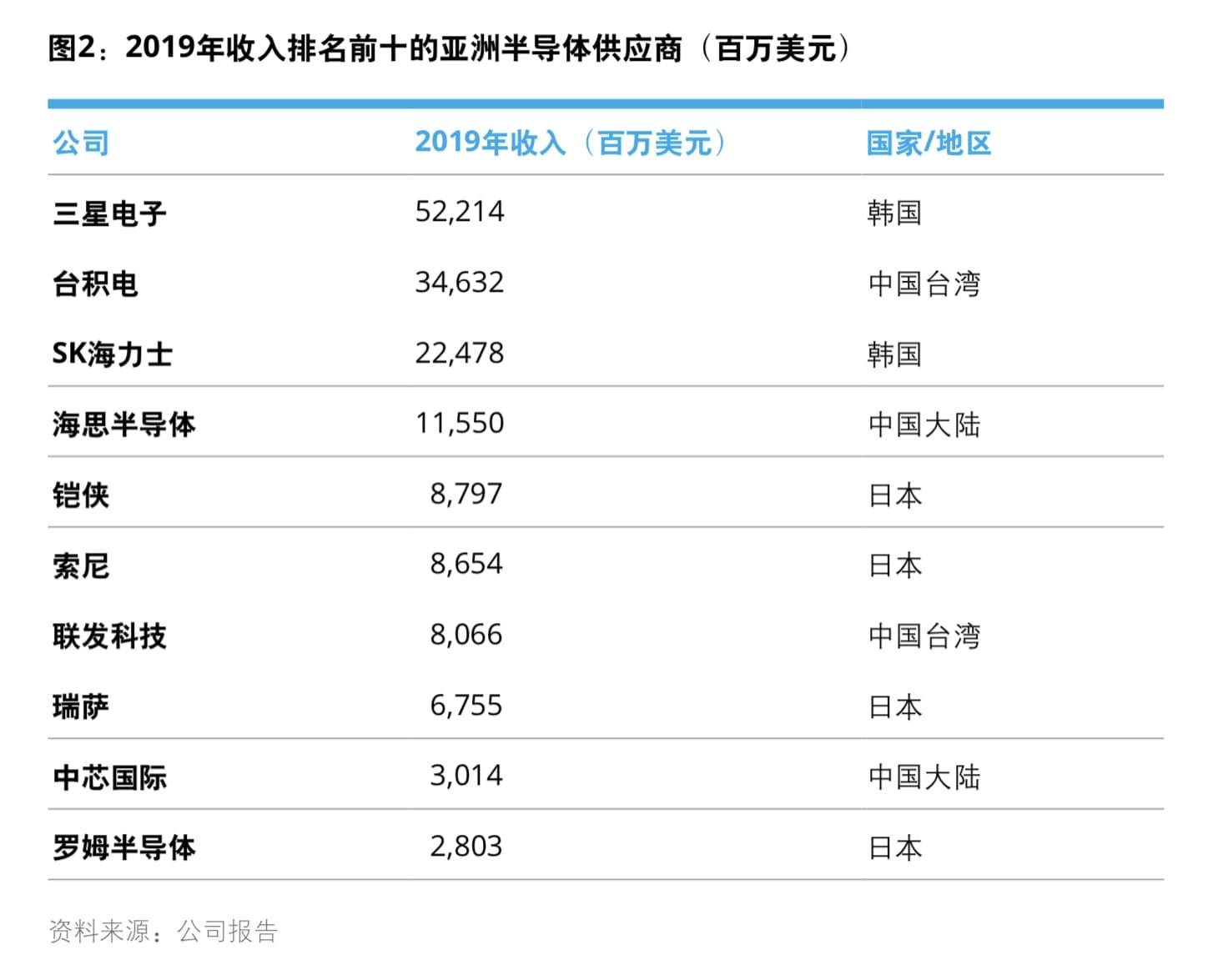
其二,亚洲地区前十大半导体公司,只有两家中国大陆公司入围,这两家公司也是大家熟悉的(华为)海思和中芯国际。
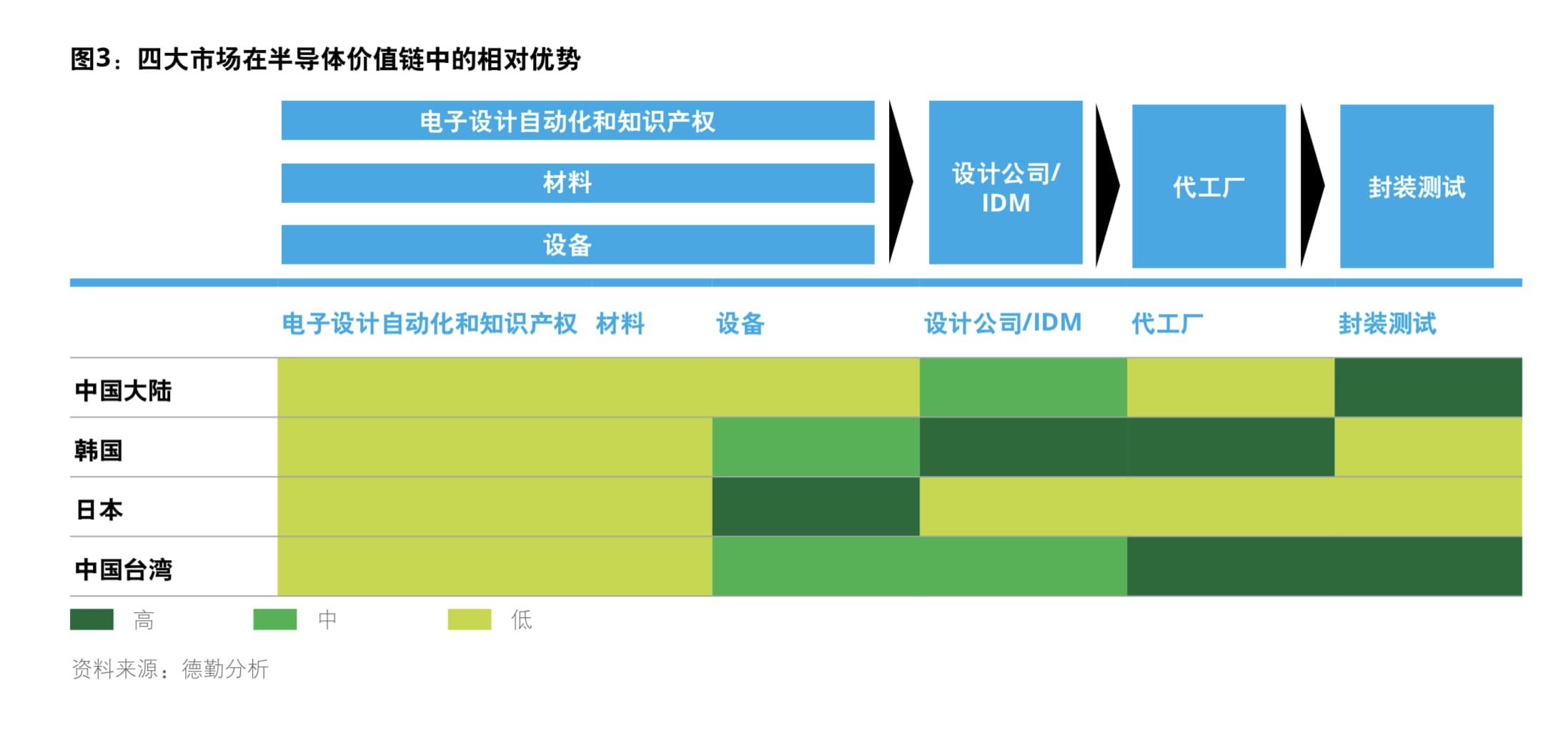
其三,围绕半导体产业链的多个环节,中国大陆有一定优势,但和其他亚洲国家/地区一样,缺乏产业链上游的知识产权、材料与设备的技术能力,这个领域属于荷兰与美国。
你可以在德勤官网免费获取这份 32 页的分析报告。
同样是围绕半导体产业链,这篇文章系统梳理了每个环节上的中国公司以及行业位置,提供非常详细的产业分类和公司发展信息,虽然呈现方式略显传统,但还是推荐一读。
正如德勤报告所指,中国在半导体产业链上需要其他国家/地区的企业和技术,因此非常有必要了解当下中美技术对抗,特别是美国针对中国半导体技术出口的限制,乔治城大学安全与新兴技术研究中心的这份报告详细整理了美国的相关技术出口限制措施。
与过往的半导体热潮不同,此次中国半导体行业发展的每一个细节,都被放在了中美技术对抗的聚光灯下,被全球各个媒体/智库分析解读,或也将成为各地政府重要的「政治任务」。在这样的背景下,从决策者到从业者,都应该尊重产业发展规律,结合当下的产业与市场特点,沉下心去做研发,才能真正实现转「危」为「机」。
|